
Hadoop - HDFS Überblick
Hadoop-Dateisystem wurde verwendung verteiltes Dateisystem-Design entwickelt. Es auf Wirtschaftsgut-Hardware laufen. Im Gegensatz zu anderen verteilten Systemen HDFS hoch fehlertolerante und ist entworfen verwendung niedrigen Kosten Hardware.
HDFS hält sehr große Menge an Daten und stellt einen leichteren Zugang. Um solche großen Daten zu speichern, werden die Dateien auf mehreren Maschinen gespeichert. Diese Dateien sind in redundanter Weise zu Rettung gespeichert, um das System vor einer möglichen Datenverlust im Falle eines Ausfalls. HDFS macht auch Anwendungen für die Parallelverarbeitung.
Eigenschaften von HDFS
- Es ist geeignet für die verteilte Speicherung und Verarbeitung.
- Hadoop bietet eine Befehlsschnittstelle, mit HDFS interagieren.
- Die eingebauten Servern auf Namen Knoten und Daten knoten Hilfe Benutzer zu einfache überprüfen den Status der Cluster.
- Streaming-Zugriff auf Dateisystemdaten.
- HDFS bietet Dateiberechtigungen und Authentifizierung.
HDFS Architektur
Da unten ist die Architektur eines Hadoop-Dateisystem.
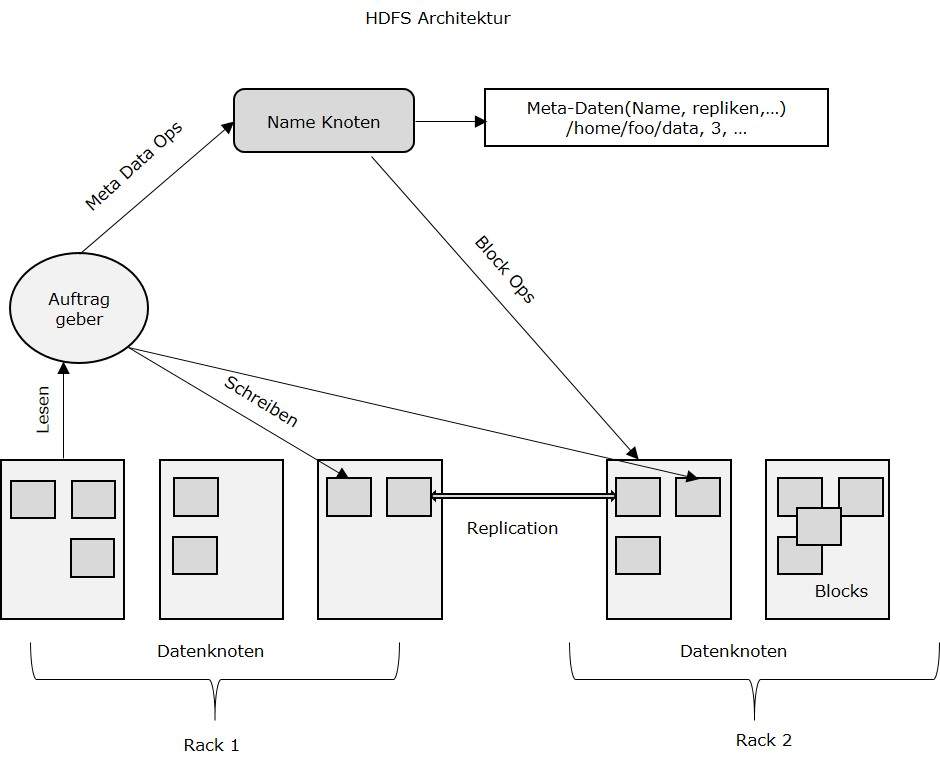
HDFS folgt der Master-Slave-Architektur und es folgenden Elemente hat.
Namen Knoten
Die Namen Knoten ist die Wirtschaftsgut-Hardware, die das GNU / Linux Betriebssystem und die Namen Knoten Software enthält. Es ist eine Software, die auf Standard-Hardware ausgeführt werden kann. Das System mit dem Namen Knoten fungiert als Master-Server und es macht die folgenden Aufgaben:
- Verwaltet die Dateisystem-Namespace.
- Reguliert Clients Zugang von zum Dateien.
- Es ausführt auch Datei system operationen wie Umbenennen, Schließen und Öffnen Dateien und Verzeichnissen.
DatenKnoten
Die DatenKnoten ist eine wirtschaftsgut-Hardware, haben die GNU / Linux-Betriebssystem und DatenKnoten Software. Für jeden Knoten (wirtschaftsgut-Hardware / System) in einem Cluster, da wird sein eine DatenKnoten. Diese Knoten Verwaltung der Datenspeicherung von ihr System.
- DatenKnoten führen Lese- Schreiboperationen auf den Dateisystemen, wie pro Client-Anfrage.
- Sie führen auch Operationen wie Block Schaffung, Löschen und Replikation gemäß den Anweisungen des Namen Knoten.
Block
Generell werden die Benutzerdaten in den Dateien des HDFS gespeichert. Die Datei in einem Dateisystem werden sein unterteilt in ein oder mehrere Segmente,und / oder in einzelnen Datenknoten gespeichert werden. Diese Dateisegmente werden als Blöcke bezeichnet. In anderen Worten, die minimale Menge an Daten, die HDFS lesen oder schreiben kann als Block bezeichnet. Die Standard-Blockgröße ist 64 MB, kann aber nach der Notwendigkeit, in HDFS Konfiguration ändern erhöht werden.
Ziele des HDFS
Fehlererkennung und Wiederherstellung: Seit HDFS umfasst eine große Anzahl von wirtschaftsgut-Hardware, ist häufige Versagen von Bauteilen. Daher, HDFS sollten haben Mechanismen für eine schnelle und automatische Fehlererkennung und Wiederherstellung.
Riesige Datensätze: HDFS sollte haben Hunderte von Knoten pro Cluster für die Verwaltung der Anwendungen mit Riesig Datensätze.
Hardware auf Daten: Die angeforderte Aufgabe effizient durchgeführt werden, wenn die Berechnung erfolgt in der Nähe von den Daten. Besonders dort, wo große Datenmengen betroffen sind, reduziert sie den Netzwerkverkehr und erhöht den Durchsatz.





