
IMS DB - Índice Secundario
Se utiliza la indización secundaria cuando lo que queremos es tener acceso a una base de datos sin utilizar la clave concatenada o cuando no queremos usar la secuencia campos primarios.
Índice Segmento Puntero
DL/I almacena el puntero a los segmentos de la base de datos indexada en una base de datos separada. Índice segmento puntero es el único tipo de índice secundario. Consta de dos partes:
- Elemento Prefijo
- Elemento de datos
Elemento Prefijo
El prefijo parte del índice puntero segmento contiene un puntero al Segmento objetivo del índice. Segmento objetivo del índice es el segmento que es accesible mediante el índice secundario.
Elemento de datos
El elemento de datos contiene el valor de clave de los segmentos en la base de datos indexada en el índice se construye. También se conoce como el índice segmentos de origen.
Estos son los puntos clave a tener en cuenta acerca de indexación secundaria:
El índice segmentos de origen y el destino, el origen segmento no tiene por que ser la misma.
Cuando nos encontramos con un índice secundario, que se mantiene automáticamente mediante el DL/I.
El administrador define muchos índices secundarios como por las múltiples rutas de acceso. Estos índices secundarios se almacenan en una base de datos de index.
No debemos crear más índices secundarios, ya que implican gastos de procesamiento adicionales en el DL/I.
Las claves secundarias
Puntos a tener en cuenta:
El campo en el índice fuente segmento en el que el índice secundario está construido es llamado como la clave secundaria.
Cualquier campo puede ser utilizado como una clave secundaria. No es necesario ser los segmentos campo de secuencia.
Las claves secundarias puede ser cualquier combinación de campos individuales dentro del índice fuente segmento.
Valores de clave secundaria no tienen que ser únicos.
Las estructuras de datos secundario
Puntos a tener en cuenta:
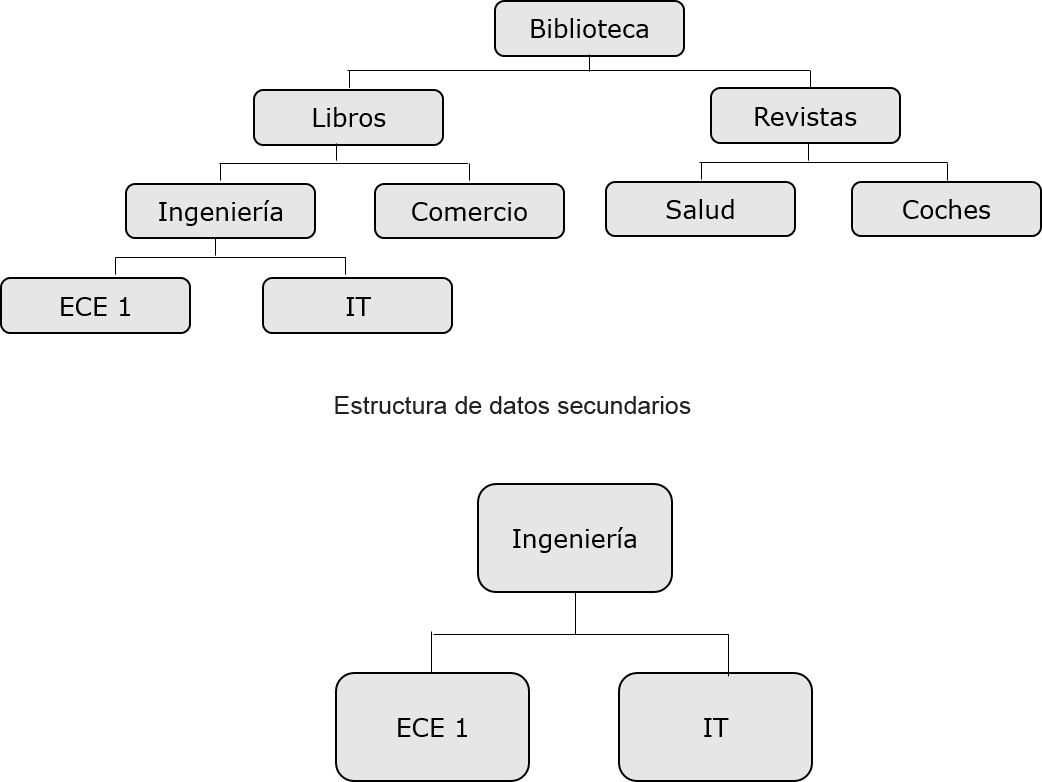
Cuando se trata de construir un índice secundario, la aparente estructura jerárquica de la base de datos está también ha cambiado.
El objetivo del índice se convierte en el segmento segmento raíz aparente. Tal como se muestra en la siguiente imagen, la ingeniería se convierte en el segmento segmento raíz, incluso si no se trata de un segmento raíz.
La reorganización de la estructura de la base por el índice secundario es conocido como secundario estructura de datos.
Las estructuras de datos secundarios no se realiza ningún cambio en la estructura de la base de datos físicos principales presentes en el disco. Es simplemente una forma de alterar la estructura de la base de datos en frente de el programa de aplicación.
Independiente y Operador
Puntos a tener en cuenta:
Cuando un Y (* o &) el operador se utiliza con índices secundarios, es conocido como un dependiente y el operador.
Un independiente Y (#) nos permite especificar las cualificaciones que sería imposible de obtener con un dependiente Y.
Este operador sólo puede utilizarse para índices secundarios donde el índice segmento fuente depende del segmento objetivo del índice.
Podemos codificar un SSA con una independiente y para especificar que una ocurrencia del sector al que se dirige se procesan basándose en los campos de dos o más segmentos origen dependiente.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.
Escasa Secuencia
Puntos a tener en cuenta:
Escasa secuencia es también conocido como escasa indexación. Podemos extraer algunas de las series del índice fuente el índice mediante secuenciación con escasa base índice secundario.
Escasa secuencia es utilizada para mejorar el rendimiento. Cuando algunas apariciones del índice fuente segmento no son utilizados, podemos quitar.
DL/I utiliza un valor de supresión o de una represión sistemática o ambos para determinar si un segmento debe ser indexado.
Si el valor de un campo de secuencia en el índice segmentos de origen coincide con un valor de supresión, sin índice se establece la relación.
La represión rutina es un programa escrito por el usuario que evalúa el segmento y determina si debe o no debe ser indexado.
Cuando se utiliza la indización dispersa, sus funciones son gestionadas por el DL/I. No se trata de hacer disposiciones especiales en el programa de aplicación.
Requisitos DBDGEN
Como se ha comentado en módulos anteriores, DBDGEN se utiliza para crear un DBD.Cuando creamos índices secundarios, dos bases de datos están involucrados. Un administrador de bases de datos debe crear dos DBDs usando dos DBDGENs para crear una relación entre una base de datos indexada y una base de datos indexada secundaria.
Requisitos PSBGEN
Después de crear el índice secundario de una base de datos, el administrador de bases de datos debe crear los órganos subsidiarios PSBGEN para el programa especifica la secuencia de procesamiento de la base de datos en el parámetro PROCSEQ del PSB macro. Para el parámetro PROCSEQ el DBA códigos el DBD nombre de la base de datos del índice secundario.





