
IMS DB - DL/I Tratamento
O IMS DB armazena dados em diferentes níveis. Os dados são recuperados e inseridos por meio da emissão DL/I chamadas a partir de um programa aplicativo. Discutiremos sobre DL/I as chamadas em detalhe no próximos capítulos. Os dados podem ser processados em duas maneiras a seguir:
- Processamento Seqüencial
- Transformação aleatória
Processamento Seqüencial
Quando os segmentos são recuperadas sequencialmente a partir do banco de dados, DL/I segue um padrão predefinido. Vamos compreender o processamento seqüencial da IMS DB.
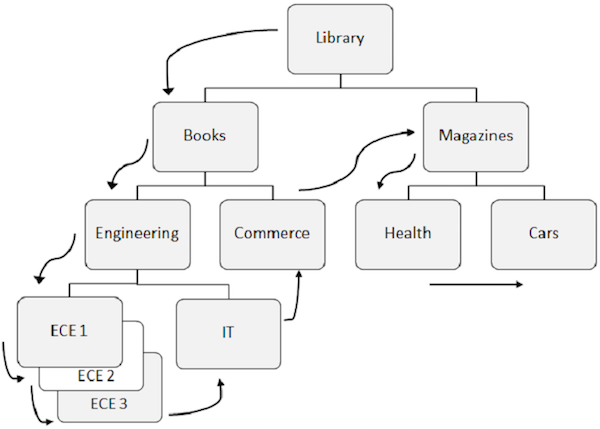
Abaixo estão listados os pontos a nota sobre processamento seqüencial.
Padrão predefinido para acessar os dados no DL/I está em primeiro lugar da hierarquia, depois à esquerda para a direita.
A raiz segmento é recuperada em primeiro lugar, em seguida, DL/I move-se para a primeira à esquerda criança e ele vai para baixo até o nível mais baixo. No nível mais baixo, ele recupera todas as ocorrências de twin segmentos. Em seguida, ele vai para o segmento direito.
Para entender melhor, observe as setas na figura acima que mostram o fluxo de acesso dos segmentos. Biblioteca básica é o segmento e o fluxo começa e vai até os carros para acessar um único registro. O mesmo processo é repetido para todas as ocorrências para obter todos os registros de dados.
Ao acessar os dados, o programa usa a posição no banco de dados que ajuda a recuperar e inserir os segmentos.
Transformação aleatória
Transformação aleatória é também conhecido como transformação directa de dados no IMS DB. Deixe-nos tomar um exemplo para entender transformação aleatória no IMS DB:
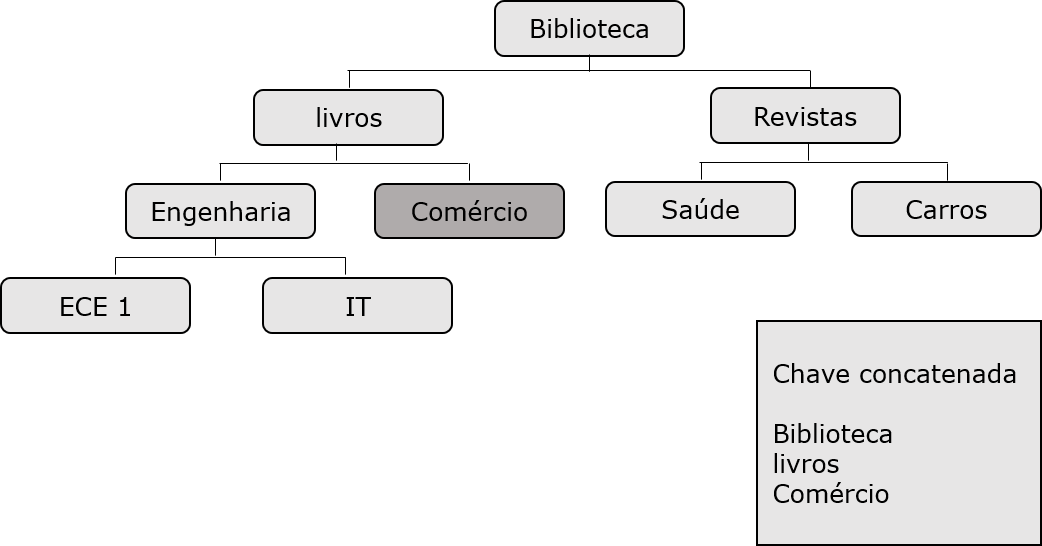
Abaixo, estão listados os pontos a nota sobre random transformação:
Segmento ocorrência que precisa ser recuperada aleatoriamente requer campos-chave de todos os segmentos que depende. Estes campos-chave são fornecidos pelo programa aplicativo.
A chave concatenada completamente identifica o caminho da raiz do segmento para o segmento que deseja recuperar.
Suponha que você deseja recuperar uma ocorrência do segmento Comércio, em seguida, você precisa fornecer a concatenados valores de campo-chave dos segmentos que depende, tais como biblioteca, livros, e o comércio.
Acaso é mais rápido do que processamento processamento seqüencial. Em cenário real, os aplicativos combinar tanto processamento seqüencial e aleatório métodos em conjunto para alcançar melhores resultados.
Campo chave
Os pontos de observação:
Um campo de chave é também conhecido como um campo de seqüência.
Um campo de chave está presente dentro de um segmento e é usado para recuperar o segmento ocorrência.
Um campo de chave administra o segmento ocorrência em ordem crescente.
Em cada segmento, apenas um único campo pode ser usado como um campo de chave ou campo de seqüência.
Campo de pesquisa
Como mencionado, apenas um único campo pode ser usado como um campo chave. Se você quiser pesquisar o conteúdo de outro segmento campos que não são os campos chave, então o campo que é usado para recuperar os dados é conhecido como um campo de pesquisa.





