
Übersetzerbau Entwurf - Syntaxanalyse
Syntaxanalyse oder Parsen ist die zweite Phase eines Compilers. In diesem Kapitel werden wir lernen die grundlegenden Konzepte verwendet in den Bau von einem Parser.
Wir haben gesehen, dass ein lexikalischer Analysator können zu identifizieren Token mit Hilfe von regulären Ausdrücken und muster Vorschriften. Aber eine lexikalische Analysator können nicht überprüft die Syntax eines bestimmten Satz aufgrund der Einschränkungen der regulären Ausdrücke. Reguläre Ausdrücke können nicht überprüfen ausgleich Token, wie Parenthese. Daher verwendet diese Phase kontextfreie Grammatik (CFG), die durch Kellerautomaten erkannt wird.
CFG, andererseits ist eine Obermenge reguläre Grammatik, wie unten dargestellt:
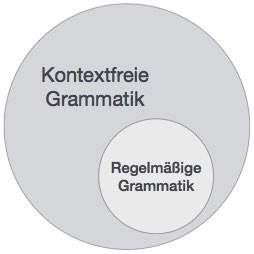
Es impliziert, dass jeder regelmäßige Grammatik ist auch kontextfrei, aber es gibt existiert einige Probleme, die über den Rahmen der regelmäßigen Grammatik sind. CFG ist ein hilfreiches Werkzeug in die Syntax von Programmiersprachen beschreiben.
kontextfreien Grammatik
In diesem Abschnitt werden wir zunächst die Definition der kontextfreien Grammatik und vorstellen Terminologien verwendet in Parsing-Technologie.
Eine kontextfreie Grammatik besteht aus vier Komponenten:
Eine Reihe von nicht-Klemmen (V). Nichtterminals sind syntaktische Variablen, die Sätze von Saiten bezeichnen. Die nicht-Terminals definieren Sätze von Saiten, die definieren, Sätze von Saiten dass helfen definieren die Sprache erzeugt durch Grammatik.
Eine Reihe von Token, bekannt als Terminal-Symbole (Σ). Terminals sind die grundlegenden Symbole aus welche Zeichenfolgen gebildet.
Eine Reihe von Produktionen (P). Die Produktionen einer Grammatik spezifizieren die Art, in der die Anschlüsse und Nicht-Terminals können kombiniert werden, um Zeichenketten zu bilden. Jede Produktion besteht aus einer Nicht-Terminal genannt linken Seite der Produktion, einem Pfeil, und eine Folge von Token und / oder on-Klemmen , genannt der Recht Seite des die Produktion.
Eine der nicht-Terminals wird als Startsymbol (S) benennen wird; von wo aus die Produktion beginnt.
Die Saite sind abgeleitet aus dem Startsymbol durch wiederholtes Ersetzen einer Nicht-Terminal (anfänglich das Startsymbol) durch die rechte Seite einer Produktion, für, dass Nicht-Terminal.
Beispiel
Wir nehmen das Problem des Palindrom Sprache, die nicht durch reguläre Ausdrücke beschrieben werden kann. Das heißt, L = {w | w = w R } ist keine reguläre Sprache. Aber es kann mittels CFG beschrieben werden, wie unten dargestellt:
G = ( V, Σ, P, S )
wo:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }
Diese Grammatik beschreibt Palindrom Sprache, wie zum Beispiel: 1001, 11100111, 00100, 1010101, 11111, usw.
Syntax-Analysatoren
Ein Syntaxanalysator oder Parser ist der Eingang von einem lexikalische Analysen in Form von Token-Streams. Der Parser analysiert den Quellcode (Token Strom) gegen die Produktionsvorschriften einhalten, um Fehler im Code erkennen. Das Ergebnis dieser Phase ist ein Syntaxbaum.
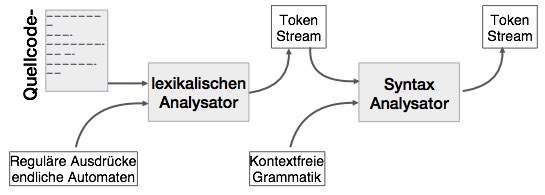
diese Weise wird der Parser erfüllt zwei Aufgaben, dh Parsen der Code, sucht nach Fehlern und zum Erzeugen eines Parsing-Baums als der Ausgang des Phasen.
Parser werden voraussichtlich den gesamten Code, auch wenn einige Fehler existieren im Programm analysieren. Parser verwenden Fehlerwiederherstellung Strategien, die wir in diesem Kapitel später erfahren.
Ableitung
Eine Ableitung ist im Grunde eine Folge von Produktionsregeln, um die Eingabe-String zu erhalten. Während der Parsen nehmen wir zwei Entscheidungen für einige Satzform der Eingabe:
- Entscheidung, das Nicht-Terminal, das zu ersetzen ist.
- Entscheidung, die Produktion der Regel, durch die, wird die Nicht-Terminal ersetzt werden.
Um zu entscheiden, welche Nicht-Terminal mit der Produktion der Regel ersetzt werden, können haben wir zwei Möglichkeiten.
Links meisten Ableitung
Wenn die sentential form eines Eingangs wird gescannt und von links nach rechts ersetzt, spricht man von ganz links Ableitung. Die sentential form abgeleitet durch der am weitesten links Ableitung wird als die linke Satzform.
Rechts meisten Ableitung
Wenn wir scannen und ersetzen Sie die Eingabe mit Produktionsregeln, von rechts nach links, wird es als äußerst rechte Ableitung bekannt. Die sentential form von der am weitesten rechts Ableitung abgeleitet ist namens als Rechtssatzform.
Beispiel
Die Produktion Regeln:
E → E + E E → E * E E → id
Die Eingabezeichenfolge: id + id * id
Die am weitesten links Ableitung ist:
E → E * E E → E + E * E E → id + E * E E → id + id * E E → id + id * id
Hinweis, dass die am weitesten links liegende Seite nicht-terminalen immer zuerst verarbeitet.
Die am weitesten rechts Ableitung ist:
E → E + E E → E + E * E E → E + E * id E → E + id * id E → id + id * id
Parse-Baum
A Parserbaum ist eine graphische Darstellung einer Ableitung. Es ist zweckmäßig, wie Saiten sind aus dem Startsymbol abgeleitet. Das Startsymbol der Ableitung wird der Stamm der Parsing-Baum. Lassen Sie uns dies zu sehen an einem Beispiel aus dem letzten Thema.
Wir nehmen der am weitesten links Ableitung von a + b * c
Die am weitesten links Ableitung ist:
E → E * E E → E + E * E E → id + E * E E → id + id * E E → id + id * id
Schritt 1:
| E → E * E | 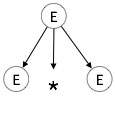 |
Schritt 2:
| E → E + E * E | 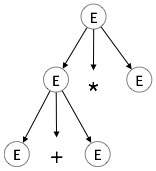 |
Schritt 3:
| E → id + E * E | 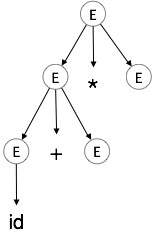 |
Schritt 4:
| E → id + id * E | 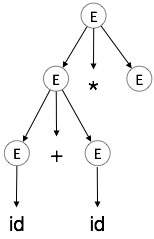 |
Schritt 5:
| E → id + id * id | 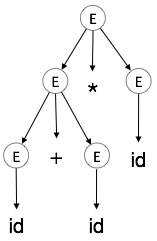 |
In einer Parsebaum:
- Alle Blattknoten sind Terminals.
- Alle Interieur Knoten sind nicht-Terminals.
- In-Order Traversal verleiht ursprünglichen Eingabestring.
Ein Parse-Baum Abgebildet die Assoziativität und Vorrang bei Operatoren. Die tiefste Unterbaum wird durchlaufen zuerst , damit die Betreiber in diesem Unterbaum bekommt Vorrang vor dem Operator, der in den übergeordneten Knoten ist.
Mehrdeutigkeit
Eine Grammatik G heißt zweideutig, wenn es mehr als einen Parsing-Baum (links oder rechts Ableitung) für mindestens einen String.
Beispiel
E → E + E E → E – E E → id
Für die string id + id - id, Obigen Grammatik erzeugt zwei Syntaxbäume:
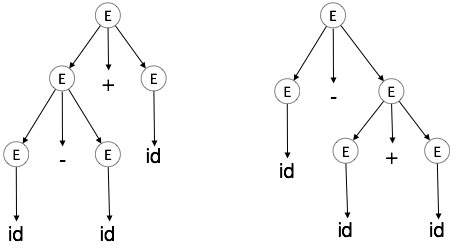
Die Sprache generiert durch einer mehrdeutigen Grammatik wird gesagt, dass von Natur aus mehrdeutig. Unklarheiten in der Grammatik ist nicht gut für eine Übersetzerbaus. Keine Methode kann erkennen und zu entfernen Mehrdeutigkeit automatisch, aber sie kann entweder durch neu zu umgeschrieben die ganze Grammatik ohne Zweideutigkeit oder durch Setzen und nach Assoziativität und Rangfolgeneinschränkungen entfernt werden.
Assoziativität
Wenn ein Operand hat Betreiber auf beiden Seiten, die Seite, auf der der Betreiber nimmt diesen Operanden wird durch die Assoziativität dieser Betreiber entschieden. Wird die Operation Linksassoziativität Dann der Operand wird ergriffen durch das links Betreiber oder wenn die Operation ist Rechtsassoziativität, die rechte Betreiber den Operanden zu nehmen.
Beispiel
Operationen wie Addition, Multiplikation, Subtraktion und der Division sind links assoziativ. Enthält der Ausdruck:
id op id op id
wird es als ausgewertet werden:
(id op id) op id
Zum Beispiel, (id + id) + id
Operationen wie Potenzierung werden recht assoziativ, dh die Reihenfolge der auswertung in gleiche ausdruck Sein Wird:
id op (id op id)
Zum Beispiel, id ^ (id ^ id)
Vorrang
Wenn zwei verschiedene Betreiber haben ein gemeinsames Operanden, der Vorrang der Operatoren entscheidet, welche den Operanden stattfinden wird. Das heißt, 2 + 3 * 4 zwei verschiedene Syntaxbäume haben, einen entsprechenden (2 + 3) * 4 und eine andere entsprechend 2 + (3 * 4). Durch das Setzen Vorrang unter den Betreibern, kann dieses Problem leicht entfernt werden. Wie im vorherigen Beispiel mathematisch * (Multiplikation) hat Vorrang vor + (Addition), also den Ausdruck 2 + 3 * 4 immer so interpretiert werden:
2 + (3 * 4)
Diese Methoden verringern die Chancen der Mehrdeutigkeit in einer Sprache oder seine Grammatik.
Linksrekursion
Eine Grammatik wird links-rekursive wenn es jedes nicht-Terminal "A", deren Ableitung enthält "A" sich als die am weitesten links stehende Symbol. Links rekursive Grammatik gilt als problematische Situation für Top-down-Parser können. Top-down-Parser beginnen Parsen aus dem Startsymbol, das an sich nicht-Terminal. Also, wenn der Parser auf die gleiche Nicht-Terminal in seiner Ableitung, wird es schwierig für sie, um zu beurteilen, wann sie aufhören Parsen des linken Nicht-Terminal und es in eine Endlosschleife geht.
Beispiel
(1) A => Aα | β
(2) S => Aα | β
A => Sd
(1)ist ein Beispiel für sofortige Linksrekursion, wobei A für ein beliebiges nicht-terminales Symbol und α repräsentiert eine Zeichenfolge von Nicht-Terminals.
(2)ist ein Beispiel eines indirekt Linksrekursion.
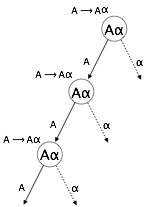
Ein Top-down-Parser wird erste prase die A, die in-turn nachgibt eine Zeichenfolge, bestehend aus A selbst und der Parser kann gehen in eine schleife für immer .
Entfernung von Linksrekursion
Eine Möglichkeit, zu entfernen Links Rekursion, ist die folgende Methode verwenden:
Die Produktion
A => Aα | β
wird in folgenden Produktionen umgesetzt
A => βA’ A => αA’ | ε
Dies tut keine Auswirkung auf die Saiten von der Grammatik abgeleitet, aber es direkt links Rekursion beseitigt.
Zweite Methode ist es, den folgenden Algorithmus verwenden, der alle direkten und indirekten linken Rekursionen zu beseitigen sollte.
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai⟹Aj𝜸
with Ai ⟹ δ1𝜸 | δ2𝜸 | δ3𝜸 |…| 𝜸
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
END
Beispiel
Die Produktion Satz
S => Aα | β A => Sd
nach dem Aufbringen des obigen Algorithmus, sollte geworden
S => Aα | β A => Aαd | βd
und dann ,entfernen sofort Sie links Rekursion verwendung dem ersten Technik.
A => βdA’ A => αdA’ | ε
Jetzt keiner der Produktion verfügt entweder direkt oder indirekt linken Rekursion.
links Factorings
Wenn mehr als eine Grammatik Produktionsregeln hat einen gemeinsamen Präfix-String, dann die Top-down-Parser kann nicht eine Wahl, welche der Produktion sollte es dauern, bis die Schnur in der Hand zu analysieren.
Beispiel
Wenn ein Top-down-Parser auf eine Produktion wie
A ⟹ αβ | α𝜸 | …
Dann kann es nicht bestimmen, welche die Produktion zu folgen, um die Zeichenfolge zu analysieren, da beide Produktionen werden ausgehend vom selben Terminal (oder Nicht-Terminal). Um diese Verwirrung zu entfernen, verwenden wir eine Technik namens linken Factoring.
Links Factoring verwandelt die Grammatik es nützlich für Top-down-Parser zu machen. Bei dieser Technik, wir machen eine Produktion für jede gemeinsame Präfixe und dem Rest der Ableitung wird durch neue Produktionen aufgenommen.
Beispiel
Die oben genannten Produktionen können geschrieben werden als
A => αA’ A’=> β | 𝜸 | …
Nun der Parser hat nur eine Produktion pro-Präfix, welche einfacher, Entscheidungen zu treffen ist.
In erster Folgen Sets
Ein wichtiger Teil der Parser Tischkonstruktion ist es, zunächst erstellen und folgen Sätze. Diese Sätze können die tatsächliche Position jedes Endgerät in der Ableitung vorzusehen. Dies geschieht, um das Parsen Tabelle zu erstellen, wenn die Entscheidung für den Ersatz T [A, t] = α mit einigen Produktionsregel.
Erster Satz
Dieser Satz wird erstellt, um, was Terminalsymbol ist in der ersten Position durch eine nicht-terminale abgeleitet. Zum Beispiel:
α → t β
Dass ist α leitet t (Terminal) in der ersten Position. Also, t ∈ FIRST (α).
Algorithmus für die Berechnung der ersten Satz
Sehen Sie sich die Definition von FIRST (α) Satz:
- Wenn α ist ein Terminal, dann FIRST (α) = {α}.
- Wenn α ist ein Nicht-Terminal und α → ℇ ist eine Produktion, dann FIRST (α) = {ℇ}.
- Wenn α ist ein Nicht-Terminal und α → 1 2 3 ... n und jede FIRST ( ) t enthält, dann ist t in FIRST (α).
Zuerst Satz kann als gesehen werden:

Follow Set
Ebenso berechnen wir, was Terminalsymbol folgt unmittelbar auf eine nicht-terminale α in Produktionsregeln. Halten wir nicht, was die Nicht-Terminal erzeugen kann, sondern sehen wir, was wäre, die die Produktionen eines nicht-terminalen folgt der nächste Terminalsymbol ist.
Algorithmus für die Berechnung der Folgen ein:
Wenn α ist ein Startsymbol und folgen Sie dann () = $
Wenn α ist eine Non-Anschluss und verfügt über eine Produktions α → AB, dann FIRST (B) ist in FOLLOW (A) außer ℇ.
Wenn α ist eine Non-Anschluss und verfügt über eine Produktions α → AB, wobei B ℇ, dann folgen (A) ist in FOLLOW (α).
Follow-Set kann als gesehen werden: FOLLOW (α) = {t | S * & agr; t *}
Grenzen der Syntax-Analysatoren
Syntax-Analysatoren erhalten ihre Eingaben in Form von Token, durch lexikalische Analysatoren. Lexikalischen Analysatoren sind für die Gültigkeit eines Tokens durch die Syntaxanalysegerät geliefert verantwortlich. Syntax-Analysatoren weisen folgende Nachteile auf -
- es kann nicht bestimmen, ob ein Token gültig ist,
- es nicht feststellen können, ob ein Token erklärt, bevor es verwendet wird,
- jedoch es nicht an, ob ein Token initialisiert werden, bevor sie verwendet wird,
- es können nicht feststellen, ob eine Operation auf einem Token-Typ durchgeführt gültig ist oder nicht.
Diese Aufgaben werden durch die semantische Analysegerät, die wir in Semantische Analyse studieren erreicht.





