
Übersetzerbau Entwurf - Top-Down Parser
Wir haben im letzten Kapitel, dass die Top-down-Parsing-Technik analysiert die Eingabe und startet Bau einer Syntaxbaum aus der Wurzelknoten und nach unten bewegen, um den Blattknoten gelernt. Die Arten von Top-Down-Analyse sind im Folgenden dargestellt:
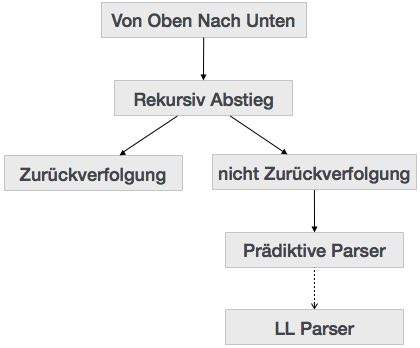
Recursive Descent Parsing
rekursive Abstieg ist ein Top-down-Parsing-Technik, die die Syntaxbaum konstruiert von der Oberseite und der Eingang von links nach rechts zu lesen. Es verwendet Verfahren für jedes Endgerät und nicht-terminalen Einheit. Diese Analyseverfahren rekursiv analysiert die Eingabe in ein Parse-Baum, die gegebenenfalls Rückverfolgung erforderlich machen werden. Aber der Grammatik zugeordnet (wenn nicht links) betragen kann nicht umhin, Rückverfolgung. Eine Form der rekursiv absteigende Parsen, die keine Rückverfolgung benötigt wird als bekannt prädiktive Analyse.
Das Parsen Technik wird rekursiv betrachtet, wie es verwendet kontextfreie Grammatik, die seinem Wesen nach rekursiv ist.
Back-tracking
Top-down-Parser starten von dem Wurzelknoten (Startsymbol ) und passen Sie die Eingabe-String an den Produktionsregeln, sie zu ersetzen (wenn angepasst). Um dies zu verstehen, nehmen Sie das folgende Beispiel für CFG:
S → rXd | rZd X → oa | ea Z → ai
Für eine Eingabezeichenfolge: lesen, einen Top-down-Parser, wird wie folgt verhalten:
Es wird mit S aus den Produktionsregeln beginnen und seine Ausbeute auf die am weitesten links stehenden Buchstaben der Eingabe entsprechen, dh 'r'. Die sehr Produktion von S (S → R · D) übereinstimmt mit ihm. So ist die Top-down-Parser zum nächsten Eingabe Brief (dh "e"). Der Parser versucht, nicht-terminale 'X' zu erweitern und überprüft dessen Produktion von links (X → oa). Er reagiert nicht mit der nächsten Eingabesymbols übereinstimmen. So ist die Top-down-Parser backtracks die nächste Produktionsregel X zu erhalten, (X → ea).
Nun ist der Parser passt alle eingegebenen Buchstaben in einer geordneten Art und Weise. Der String wird angenommen.
|
|
|
|
|
Predictive Parser
Predictive-Parser ist ein rekursiv absteigenden Parsers, der die Fähigkeit, vorherzusagen, welche die Produktion verwendet werden, um den Eingabestring zu ersetzen hat. Die Vorhersage Parser nicht aus Backtracking zu leiden.
Zur Erfüllung seiner Aufgaben verwendet die Vorhersage Parser eine vorausschauende Zeiger, der auf die nächste Eingabezeichen zeigt. Um den Parser Rückverfolgungs frei, legt der prädiktiven Parser einige Einschränkungen für die Grammatik und akzeptiert nur eine Klasse von Grammatik LL (k) Grammatik bekannt.
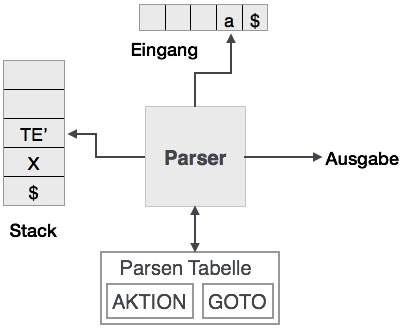
Predictive Analyse verwendet einen Stapel und einen Parsing-Tabelle, um die Eingabe zu parsen und erzeugen einen Syntaxbaum. Sowohl der Stapel und der Eingang enthält ein Endsymbol $, um anzuzeigen, dass der Stapel leer ist und der Eingang verbraucht wird. Der Parser bezieht sich auf die Analyse-Tabelle, die Entscheidung über die Ein- und Stapelelementkombination zu nehmen.
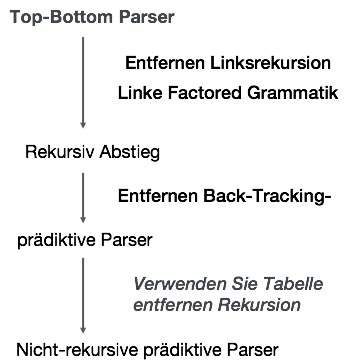
rekursiv absteige Parsing kann der Parser mehrere Produktion von für eine einzelne Instanz von Eingabe zu wählen, während bei prädiktiven Parser weist jeder Stufe höchstens eine Produktion zu wählen. Möglicherweise gibt es Fälle, in denen es keine Produktion Anpassung der Eingabezeichenfolge, so dass die Analyse vor, um nicht sein.
LL Parser
Ein LL Parser akzeptiert LL Grammatik. LL-Grammatik ist eine Teilmenge der kontextfreien Grammatik, aber mit einigen Einschränkungen, die vereinfachte Version zu erhalten, um eine einfache Implementierung zu erreichen. LL-Grammatik kann mit Hilfe der beiden Algorithmen zwar umgesetzt werden, rekursiv absteigende oder tabellengesteuert.
LL-Parser wird als LL (k) bezeichnet. Der erste L in LL (k) Analysieren des Eingangs von links nach rechts, der zweite L in LL (k) steht für die am weitesten links Ableitung und k selbst stellt die Anzahl der Look aheads. Im allgemeinen k = 1, so LL (k) auch als LL geschrieben werden (1).

LL Parsing Algorithm
Wir können determinis LL (1) Parser für die Erklärung zu bleiben, wie die Größe der Tabelle wächst exponentiell mit dem Wert von k. Zweitens, wenn ein gegebener Grammatik nicht LL (1), ist es dann meist nicht LL (k) für jede gegebene k.
Da unten ist ein Algorithmus für LL (1) Parsing:
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol)
ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */
Eine Grammatik G ist LL (1), wenn A & rarr; α | β sind zwei verschiedene Produktionen von G:
für nicht Terminal, sowohl α und β abgeleitet Saiten Start mit ein.
höchstens eine der α und β können leere Zeichenkette abgeleitet werden.
wenn β & rarr; t, dann α keine String beginnend mit einem Terminal in FOLLOW (A) abgeleitet werden.





